Mettre en place une stratégie de sauvegarde
Rédigé par Fenix - - 13 commentairesFaire des sauvegardes, ce n'est pas négociable. Qu'on soit étudiant.e, avec son mémoire ou sa thèse en cours de rédaction sur une clé USB, parent.e, avec les archives photos de toute la famille sur un vieux PC portable en fin de vie, ou chef.fe d'entreprise, avec sa comptabilité sur 10 ans dans un fichier Excel dans une Dropbox, TOUT LE MONDE doit se préparer à la perte de ses données un jour ou l'autre. C'est inéluctable, ça peut être tragique (pour une entreprise, ça peut impliquer la faillite pure et simple), mais heureusement on peut préparer quelques filets de sécurité.
Essayons de voir comment limiter la casse le jour où vous allez oublier votre PC portable dans le train ou que votre stagiaire plantera votre production...
Disclaimer : cet article ne s'adresse pas du tout à des professionnel.le.s de la sauvegarde, mais plutôt à des non-initié.e.s ou des administrat.eur.rice.s de TPE/PME qui n'ont pas forcément beaucoup de ressources à y accorder. Certaines problématiques sont simplifiées pour rester abordables, l'idée est de faire un tour d'horizon rapide de celles-ci. Je base ce retour d'expérience sur les différents contextes que j'ai traversé (auto-hébergement, associatif, TPE/PME en pleine expansion, groupe international ou encore organisme public, pour des volumétries allant de quelques Go à plusieurs Po), et toute remarque constructive sera la bienvenue pour faire évoluer cet article !
Pourquoi faire des sauvegardes ?
Comme déjà rapidement abordé en introduction, perdre des données arrive à tout le monde, n'importe quand, et en particulier au plus mauvais moment.
Pour un particulier, c'est déjà compliqué de faire le deuil de ses photos de famille, alors que dire d'une entreprise qui perd son référentiel de clients, ses bons de commandes ou ses montages vidéos pour la prochaine campagne publicitaire ?
On peut facilement jouer les médiums, ici :
- à la fin de la première heure, c'est le chaos : on court dans tous les sens pour essayer de récupérer ce qu'on peut sur les PC des uns et des autres ;
- à la fin de la première journée, les réunions de crise passées, le constat est clair : l'activité est arrêtée, c'est le chômage technique ;
- à la fin de la première semaine... c'est cuit.
Parce que remonter dans les archives papiers (s'il en reste et si ça a le moindre sens, selon votre activité) prend du temps, et que pendant ce temps vos clients vous lâchent. Parce que votre réputation en prend un sacré coup. Et parce qu'une partie de vos employé.e.s baisseront tout simplement les bras devant la charge de travail, alors qu'ils/elles vous avaient prévenu depuis des mois...
Faire des sauvegardes (fonctionnelles), c'est un gage de sécurité, voire de survie. Oui, ça engendre un coût, mais comparez-le 30 secondes avec le coût d'un arrêt de votre production pendant 3 jours ou l'impossibilité de vous présenter à votre soutenance après 3 années de travail intense. Etes-vous vraiment prêt.e à sacrifier quelques centaines d'euros pour risquer de perdre des années de votre vie ? (au passage, cette réflexion est également valable pour vos autres outils de travail au quotidien : vous économisez à tout va en ne prenant qu'un accès Internet grand public chez Free pour votre agence de 120 personnes, faites le calcul des pertes engendrées par une interruption de 3 jours parce que vous avez réfusé de prendre un second accès chez un autre opérateur, ou une garantie de rétablissement en 4H avec un forfait professionnel adapté).
Et ça n'arrive pas qu'aux petites structures : des grands groupes qui négligent les sauvegardes, il y en a légion. Et mettre de l'argent sur la table ne suffit pas : il faut définir une vraie politique de sauvegarde et mettre les moyens humains, techniques et opérationnels en place pour s'en occuper tous les jours.
J'ai personnellement vu des choses effrayantes, comme des bases Oracles derrière des applications de billetique (et brassant des millions d'€/mois) ne pas être sauvegardées, parce que les différentes équipes systèmes/applicatives et les SSII au-dessus se renvoyaient la balle depuis des mois.
J'ai personnellement connu une entreprise, qui a fermé, perdre l'intégralité de ses clients en 2 jours parce qu'ils avaient tout misé sur AWS (Amazon Web Services) : on leur vendait une architecture ultra-redondée, blindée et à l'état de l'art, et la simple perte d'un bucket S3 (espace de stockage objet) non sauvegardé (par négligence) a suffit à ruiner des années de travail (et une amie m'a rapporté une situation analogue récemment).
J'ai personnellement connu un étudiant en école d'ingénieur qui a vécu une situation personnelle tragique, quand après des mois de travail acharné pour son mémoire de dernière année (avec une concurrence extrêmement forte entre les élèves, entretenue par l'administration au nom du sacro-saint "classement" des grandes écoles) il s'est fait volé son PC portable dans un bus. Dépression grave, arrêt de ses études, et après 5 années d'aléas il commence tout doucement à sortir la tête de l'eau.
Comment je fais, alors ?! Il est où le bouton magique ??
Spoiler : il n'y en a pas. Et cet article n'a pas vocation à vous fournir un script tout prêt qui vous sauvera la vie, tout simplement parce que rien n'est aussi simple. Dans un premier temps, nous allons essayer de comprendre quelles sont les étapes importantes de la réflexion à mettre en place.
1 - Quoi ?
La première étape consiste "tout simplement" à essayer de déterminer ce qui DOIT être sauvegardé. Dans le cadre d'une entreprise, par exemple, il semble logique de vouloir sauvegarder tous les documents comptables, clients, etc... quand pour un particulier on pensera en premier lieu aux documents personnels et aux photos de famille. Cette opération peut sembler triviale, et pourtant... Pourtant, vous oublierez toujours un répertoire, une base de données, ou le PC du stagiaire qui avait mis en place votre site Web il y a 2 ans et dont les sources sont toujours sur le disque, au fond du placard. A l'inverse, vous pourrez très bien vous attacher à des données sans intérêt, par exemple des exports de votre ERP que vous pourrez très bien re-générer au besoin, ou la collection de PowerPoint de chats que vos collègues vous envoient à longueur de journée et que vous gardez "précieusement" dans vos téléchargements... A vous de bien inventorier votre système d'information (ou "SI") pour ne rien oublier, mais de ne pas non plus tomber dans l'excès inverse et vous étrangler devant le volume de données à sauvegarder (le stockage, ça coûte cher, mais on y reviendra).
Posez-vous toujours les questions suivantes :
- Ce document est-il vital pour mon entreprise ? (AKA : si je le perds, quelles sont les conséquences pour mes client.e.s et mes salarié.e.s ?) ;
- Si non : est-ce que ça vaut le coup de faire augmenter ma facture de sauvegarde pour lui ? (pensez aux Powerpoint de chats susnommés) ;
- Si oui : ne vous posez même pas la question, SAUVEGARDEZ.
Mais attention : sauvegarder des documents, c'est une chose, mais encore faut-il pouvoir en tirer quelque chose si vous perdez le reste de votre SI.
- Exemple 1 : en bon expert comptable, je sauvegarde méticuleusement mes archives Excel/Word/PDF, mais pas mes applications Sage/Ciel/whatever qui me permettent de les exploiter. Si je perds mon poste de travail, il me faudra donc réimporter tout ça de zéro, perdant ainsi des journées (semaines ?) entières.
- Exemple 2 : je suis responsable d'une application qui tourne sur une base Oracle + un Tomcat pour une administration quelconque. Je demande bien à l'équipe système en charge des bases Oracle de la sauvegarder, aux développeurs de conserver les .war qui vont bien, mais j'oublie de demander à l'équipe système en charge des Linux de sauvegarder les configurations de mon Tomcat (ou alors, je fais bien la demande mais comme je suis brouillé avec leur responsable, celle-ci est gentillement mise "dans la TODO"). Résultat : application non-restaurable.
Côté système, justement, il faut bien voir que simplement sauvegarder les fichiers de configuration de votre application peut ne pas suffire : au cours de la vie d'une application, des librairies supplémentaires sont ajoutées, des configurations spécifiques côté réseau/firewall/stockage sont appliquées, et un certain contexte humain/managérial peut venir se greffer (comme dans l'exemple ci-dessus). Il peut donc être utile de viser large, en sauvegardant trop de choses plutôt que pas assez. Comme vous êtes vigilant, vous penserez bien entendu à exclure des répertoires comme les /proc, /tmp et j'en passe, qui n'ont absolument aucun intérêt mais peuvent alourdir la facture.
Tiens, au passage, côté Microsoft : inutile de copier "à la main" l'intégralité du disque, en particulier le C:\Windows, car il n'est pas possible de le restaurer par une simple copie. Il faudra passer par des outils spécifiques, souvent payants, ou bien prendre en compte le temps et les coûts de réinstallation de vos Windows (puis de la restauration des données).
A noter, bien sûr, qu'à l'ère de la virtualisation à tout va (et c'est tant mieux !), il peut être très pratique de conserver au moins une sauvegarde complète de chaque VM, pour pouvoir la remonter au besoin et n'avoir à restaurer que le delta avec votre dernière sauvegarde (et éviter de réinstaller votre Windows, au passage). Inconvénient : il faut que ça soit prévu avec votre environnement de virtualisation, et ça prend de la place (sans compter les éventuelles incrémentales qui pourront suivre).
A noter (bis), que si vos plateformes sont intégralement gérées par des outils de configuration management, versionnées, conteneurisées et j'en passe, la restauration peut être assez rapide. Attention par contre aux données, qui seront la plupart du temps stockées en dehors de ces référentiels.
2 - Quand ?
Maintenant que vous savez à peu près quoi sauvegarder, abordons les notions de planification et de rétention.
Il faut déjà prendre en compte l'état des données que vous souhaitez sauvegarder : si vous opérez un traitement sur des lots de fichiers à 22h, il semblerait logique d'attendre la fin de celui-ci avant de les récupérer. Si vous hébergez des plateformes Web, pensez bien que celles-ci s'appuyent certes sur des fichiers php/css/whatever, mais aussi sur des bases de données, voire sur d'autres applications métiers : sauvegarder ces éléments à des horaires différents résultera en une incohérence de vos jeux de sauvegarde applicatifs, et leur restauration risque donc de vous laisser avec une plateforme inexploitable...
Planifiez par application/environnement en priorité, pas par machine !
Deuxième contrainte : la charge engendrée par les sauvegardes sur vos plateformes. Selon les outils que vous allez utiliser, vous allez générer une charge CPU/RAM et de forts I/O (accès entrées/sorties sur vos données) sur vos machines, pendant un temps certain, ce qui peut impacter votre production (à noter que certains outils de sauvegarde permettent de fixer des limites ou des priorités sur les ressources exploitables). Il peut donc être intéressant de procéder en plusieurs étapes, par exemple en ne sauvegardant qu'un serveur frontal sur deux à la fois (soit par des jeux différents, soit en parallélisant intelligemment vos opérations).
Côté réseau, les flux de sauvegarde sont très souvent négligés, et on se retrouve avec des congestions à 2h du matin, même (surtout) dans de très grosses structures... A titre personnel, j'ai pris l'habitude de systématiquement y dédier une interface sur mes hyperviseurs et mes serveurs : même si elle sature, elle n'impactera pas les flux de production de cet hôte (reste à dimensionner vos backbones correctement aussi, et à bien étudier vos diagrammes de flux pour essayer de rapprocher vos serveurs de sauvegarde des plateformes qu'ils vont accueillir). Évitez donc de lancer de gros jeux de sauvegarde en simultané à un moment où vos plateformes/tuyaux sont occupé.e.s : privilégiez des périodes creuses, ou procédez au compte-goutte en fonction des plateformes tout au long de la journée. Il peut par exemple être intéressant de sauvegarder les données utilisateurs dès la fin des horaires de bureau (voire en flux continu, aujourd'hui), pour conserver de la bande passante à 23h pour votre production.
3 - Combien de temps ?
Parlons rétention, à présent. Déjà, il est intéressant de distinguer sauvegarde et archivage :
-
on parlera généralement d'archivage pour des rétentions longues, potentiellement hors-site ou hors-ligne, ou pour des données "froides" à conserver dans un coin pour des raisons légales, par exemple ;
- la sauvegarde, quant à elle, concernera des données chaudes pertinentes à garder sous la main pour des restaurations rapides en cas de besoin.
Typiquement, on pourra envisager des sauvegardes sur une semaine ou un mois maximum, soit des données encore éventuellement pertinentes pour votre production actuelle, puis on migrera au-delà sur une solution d'archivage pour garder un historique. Il faut noter que le temps de restauration depuis vos sauvegardes doit être le plus court possible, là où depuis vos archives on se permettra une latence plus importante : à ce titre, attention aux outils que vous utiliserez, car certains devront consulter/générer un catalogue pour aller trouver les données demandées, et ça peut prendre du temps...
A titre d'exemple, je gèrais il y a encore peu de temps plusieurs centaines de jeux de sauvegarde (professionnels et personnels), dont certains avec des rétentions d'un an (pour des raisons contractuelles) : bien entendu, les données stockées qui datent d'il y a 11 mois, bien qu'intègrent, n'ont plus aucun intérêt pour la production... mais prennent bien de la place (pour rien ?). Attention également à l'intégrité de vos données dans le temps, justement : dans le cas de l'archivage, celles-ci ne seront plus modifiées pendant des périodes assez longues, et des corruptions silencieuses peuvent tout à fait se produire (n'oubliez pas que, sous les bits, il y a de l'électronique). Il est important d'utiliser des supports spécialisés (type bande magnétique) ou des outils qui veilleront régulièrement au bon état des données.
Et en parlant de stockage, voici notre dernier point d'attention : quelles volumétries occuperont mes sauvegardes ? Ici, difficile d'avoir une estimation précise : tout dépendra du type de données (peuvent-elles être compressées ?) et de leur volatilité (si mon jeu de donnée change intégralement tous les jours, je stocke chaque jour 100% de nouvelles données). On peut estimer, dans une moyenne au doigt mouillé, qu'un coefficient de x1,5 est une bonne base de départ pour une rétention de 7 jours, mais il faut surveiller régulièrement l'espace utilisé et les besoins à venir pour ne pas se retrouver pris au dépourvu la veille d'un week-end...
Cette problématique est également liée au support/système de sauvegarde que vous allez utiliser : si celui-ci permet de faire de la compression, voire de la déduplication, alors vous pouvez espérer des gains très intéressants.
- Exemple 1 : sur mon jeu annuel que j'évoquais plus haut, et qui concerne environ 150 machines aux applicatifs variés (environ 98% sous Linux), j'ai un taux de compression de 2 sur mon serveur de sauvegarde qui s'appuie en partie sur ZFS, soit ~42To de données réelles compressées en ~21To.
- Exemple 2 : sur un jeu de 700Go concernant un environnement Nextcloud de 5 VM et qui héberge quelques dizaines d'utilisateurs (les données sont ici versionnées, il peut donc y avoir énormément de redondance), j'obtiens un ratio de 2.9 avec un outil me permettant de faire de la déduplication (703Go initiaux stockés dans 245Go).
4 - Comment ?
Donc, nous avons à présent un aperçu de nos contraintes : il est temps de s'intéresser aux outils et méthodes.
Avant toute chose, comme pour TOUT projet, ne tombez pas, S'IL VOUS PLAIT, dans le piège classique de la facilité ou du pur intérêt financier : définissez correctement vos besoins, étudiez les possibilités qui s'offrent à vous, faites des tests et choisissez l'outil le mieux adapté ! Ce n'est pas parce que votre parc est 100% Linux que vous devez exclure toutes les solutions payantes/propriétaires de votre étude (même si on préférerait évidemment rester sur du Logiciel Libre) : si votre besoin est mieux couvert par tel ou tel outil, ne cherchez pas à bricoler un truc bancal dans un coin que vous regretterez dans 1 an...
A titre d'exemple (pour un particulier), si vous souhaitez sauvegarder votre Windows ce n'est pas la peine de choisir un outil gratuit récupéré sur Clubic ou de bricoler un script qui fera du rsync avec Cygwin : vous sauvegardez peut-être bien vos données, mais jamais vous ne pourrez restaurer votre système. Utilisez peut-être tout simplement l'outil de sauvegarde intégré à Windows : oui, il est perfectible, mais il fera tout de même mieux le job car il est pensé pour ce besoin dès le départ.
On peut distinguer plusieurs types de sauvegardes (pour les fichiers) :
- En mode "fichier" : On copie chaque jour les fichiers qui ont été modifiés, ou des parties seulement de ces fichiers, d'un volume source vers une volume de destination.
Cette méthode est clairement la plus simple à mettre en place, les outils sont légions, le premier étant la copie manuelle vers votre clé USB. L'inconvénient principal, c'est que la majorité de ces outils ne sont pas suffisamment intelligents pour détecter quelles parties de vos fichiers ont bougé : ainsi, si vous avez édité un fichier vidéo de 4Go pour y ajouter des sous-titres, par exemple, vous en serez quitte pour recopier à nouveau la totalité de ces 4Go pour votre prochaine sauvegarde (le fichier a changé, mais impossible pour votre outil de savoir à quel endroit exactement). A noter que d'autres outils travailleront plus finement, et découperont vos fichiers en morceaux pour détecter justement au mieux ce qui a pu bouger, et ne copier que la différence. - En mode "bloc" : Généralement au niveau du système de fichiers ou du votre environnement de stockage.
Ici, on gagnera clairement en efficacité, pour plusieurs raisons :- D'abord, on détectera les données modifiées de façon très fine, car on ne s'attardera pas forcément sur leur représentation haut niveau (une image, une vidéo, un tableur...) mais plutôt sur la suite de bits/d'octets qui les composent : une suite de 0 et de 1 modifiée, c'est une donnée modifiée, donc mon système de sauvegarde ne s'occupe que de ces quelques altérations.
- Si on travaille directement au niveau du backend de stockage (baie de disque, volume logique...), on ne passe pas par le système de fichier, ce qui veut dire qu'on s'économise un certain nombre de latences sur les temps d'accès. En effet, quand vous tentez d'accéder à une donnée, vous demandez à votre système de fichier d'aller vous chercher une suite d'octets spécifique (votre mémoire de fin d'année, par exemple), cette suite étant identifiée et repérée par un mécanisme de pointeurs (d'annuaire) qu'il faut maintenir, consulter, etc...
Pour les bases de données ou autres structures qui vont vivre intensément en mémoire vive, la sauvegarde ne peut pas s'opérer de cette façon. Les données sont bien écrites régulièrement sur vos disques, mais le delta peut s'avérer important et vous pouvez également vous retrouver avec des jeux de données incohérents sur vos disques (plusieurs bases qui n'ont pas été écrites en même temps, par exemple). Concrètement, sur l'exemple d'un MySQL, sauvegarder votre /var/lib/mysql n'est pas forcément suffisant pour restaurer votre application métier : un "dump" sera déjà beaucoup plus pertinent, car (avec les bonnes options) il vous permettra de récupérer une archive cohérente de votre base à un instant T. Les binary logs peuvent également vous aider (ils enregistrent toutes les transactions), car il vous suffit alors de rejouer les opérations manquantes depuis votre votre dernier dump (le temps de créer celui-ci, de nouvelles opérations étaient déjà en cours sur votre base...), mais vous voyez rapidement qu'il faut procédurer et outiller finement ces opérations de sauvegarde/restauration pour ne pas se retrouver le bec dans l'eau... A noter qu'il existe des applications permettant de sauvegarder "à chaud" vos bases de données, c'est-à-dire que chaque transaction est également sauvegardée directement (soit elle sera rejouée automatiquement à la restauration, soit un "dump" virtuel est généré à chaque transaction pour réduire le temps de restauration). Les bases de données ("traditionnelles" ou "non-structurées", si je m'autorise un raccourci grossier) sont un sacré sujet à elles toutes seules, et comme ce n'est pas foncièrement ma spécialité je n'irai pas plus loin ici :D
Poursuivons sur le thème de la cohérence des données, justement : si vous optez pour une simple copie de vos fichiers, cette copie prend du temps. Or, durant ce temps, vos données peuvent vivre.
Prenons l'exemple d'un lot de 1000 fichiers sur lesquels vous appliquez un traitement :
- vous démarrez votre sauvegarde à 18h ;
- vous copiez en quelques minutes les 100 premiers fichiers, qui ne sont pas encore traités ;
- à 18h15, votre traitement (que vous aviez oublié de prendre en compte dans votre planification) modifie les 1000 fichiers ;
- votre copie continue, et les 900 autres fichiers sauvegardés sont donc à présents traités ;
- au final, vous vous retrouvez avec un lot de 1000 fichiers qui n'est pas cohérent : tous ne sont pas dans le même état (traités/pas traités).
Cette situation est très fréquente, car on ne pense pas forcément à tous les traitements qui s'opèrent sur notre SI. C'est toujours dans le cas d'une restauration d'urgence que l'on constate que les jeux de données ne sont pas cohérents, et qu'on va donc devoir, au mieux, réappliquer une partie des traitements sur une partie des données (retardant d'autant la remise en fonction du service). Dans le pire des cas, les données ne sont tout simplement plus exploitables, le service ne peut pas être relancé.
L'une des solutions pour se prémunir de cette situation est de ne plus sauvegarder vos données "vivantes", mais de travailler sur un instantané de celles-ci : vous prenez une "photo" de votre répertoire/système de fichier/VM/SGBD, et vous sauvegardez cette photo. Vous avez ainsi l'assurance que les données sont dans un état cohérent tout au long de la sauvegarde (attention : elles ne le sont pas forcément d'un point de vue applicatif, car un traitement pouvait tout de même être en cours, mais c'est déjà un début). A noter que, si vos plateformes reposent sur des socles de virtualisation, la plupart des solutions de sauvegarde qui s'y greffent travaillent justement en mode "snapshot", pour que vos VM soient figées (un clone virtuel, hein, pas votre production) au moment de la sauvegarde (même si, *attention*, ce snapshot ne peut pas forcément tenir compte de l'état de vos données/traitement *à l'intérieur* des VM, chacun son travail).
RAID1 =/= sauvegarde
Ce premier petit tour d'horizon étant fait, petit aparté "rapide" en passant, parce que j'y pense : le RAID1 N'EST PAS une solution de sauvegarde. Elle est vendue comme telle par beaucoup de fabricants de NAS ou des "boutiques d'informatique du coin", entre autres, mais c'est une hérésie. Oui, un miroir vous protégera d'une défaillance matérielle sur l'un des 2 volumes, mais en aucun cas il ne préviendra d'une erreur humaine (altération ou suppression d'une donnée), d'un bug (au pif, le RAID n'est plus reconnu ou le système de fichier est corrompu, comme je le vois régulièrement sur des NAS Western Digital ou Netgear), ou d'un acte malveillant (pensez ransomwares). RAID1 =/= sauvegarde, point final. Et cette assertion est également vraie pour vos systèmes en haute-disponibilité (par exemple vos bases de données dont nous avons parlé il y a peu) : une réplication, synchrone ou pas, N'EST PAS une sauvegarde, puisque, par définition, elle réplique tout, y compris les erreurs.
J'aimerais évoquer ici l'exemple (personnel) d'une mairie, d'une commune d'environ 1000 habitants, qui avait souhaité faire évoluer son SI (composé de 4 PC sous diverses versions de Windows). N'ayant aucune compétence en informatique sous la main, le maire avait décidé d'en appeler à une petite boutique d'une ville voisine (vous savez, le genre de boutique où vous pouvez faire "désinfecter" votre Windows et où vous repartez en réalité avec un PC réinstallé, sans vos données, et avec une licence piratée... bref). Fort de son expertise, le tenant de la boutique avait vendu à la mairie un NAS Netgear avec 2 disques en RAID1, ventant la sécurité absolue des données ainsi stockées. Ce qui devait arriver arriva : le NAS tomba en panne (la qualité des firmwares Netgear, tout ça tout ça...), et le maire s'adressa donc au susnommé expert qui lui avait vendu la solution pour trouver une solution (la mairie ne pouvait plus fonctionner, tout l'administratif étant stocké dessus). Et ledit expert, en panique après une grosse journée "d'analyse", ne trouva comme solution que l'envoi d'un des deux disques à une société de récupération de données, pour la coquette somme de 1500€ (qu'il allait refacturer à la mairie, bien entendu). Quand j'ai eu vent de l'histoire, le soir même, je me suis rendu à la mairie, ai récupéré le second disque et laissé tourner toute la nuit un petit outil libre de récupération de données (dont j'ai depuis oublié le nom, malheureusement). Le lendemain matin, le maire récupérait ses 700Go de Word/Excel/PDF/etc ; nous n'avons jamais eu de retour de la société de récupération de données, ni de la boutique.
Trois conclusions :
- le libre, c'est plus fort que tout ;
- le RAID1 N'EST PAS UNE SAUVEGARDE (je crois que je l'ai déjà dit, non ?) ;
- adressez-vous à des professionnels (même si c'est parfois dur de les identifier).
Full / incrémentale / différentielle
Petit point vocabulaire, qui a son importance (attention, ça peut être dense).
Dans le monde de la sauvegarde, on va distinguer plusieurs méthodes d'exécution des sauvegardes, et chacune aura des implications propres :
- La sauvegarde "full", ou "complète" : on copiera, à chaque exécution du jeu, l'intégralité des données clientes.
- Avantage(s) :
- On s'assure que notre jeu de données sauvegardées est complet et a priori cohérent ;
- En cas de restauration, il ne sera pas nécessaire de reconstruire des index ou de parcourir des catalogues quelconques pour restaurer nos données : elles sont juste là, sous nos yeux.
- Inconvénient(s) :
- On va consommer énormément de ressources : côté client, le trio CPU/RAM/IO sera sollicité aussi brutalement tous les jours ; côté serveurs, la volumétrie va exploser.
- Avantage(s) :
- La sauvegarde "incrémentale" : chaque jeu se basera sur les données du jeu précédent et se contentera d'opérer une copie des seules différences depuis les machines clientes. On se retrouvera avec une sorte de millefeuille, ou chaque couche est ajoutée une à une, et où le réel intérêt ne réside que dans toutes les strates prises dans leur ensemble.
- Avantage(s) :
- Beaucoup plus rapide qu'une sauvegarde complète, puisqu'on se contente de gérer les quelques différences ;
- Beaucoup plus économe en ressources, que ça soit d'un point de vue CPU/RAM/etc que d'un point de vue réseau, et surtout STOCKAGE.
- Inconvénient(s) :
- Selon la quantité d'incrémentales, votre millefeuille peut vite devenir effrayant, voire risquer de perdre en cohérence ;
- En cas de restauration, il faudra parcourir récursivement toutes les strates du millefeuille pour obtenir un jeu de données exploitable. Cette opération peut s'avérer assez longue et coûteuse en ressources (côté serveur, essentiellement).
- Avantage(s) :
- La sauvegarde "différentielle" : chaque jeu opérera une incrémentale, non pas à partir de la précédente incrémentale mais à partir de la dernière "full".
- Avantage(s) :
- Plus rapide qu'une sauvegarde complète ;
- Moins de ressources consommées qu'une complète (surtout côté stockage) ;
- En cas de restauration, il sera beaucoup plus rapide de reconstruire votre jeu de données à partir d'une "full" + d'un delta que dans le cas d'un millefeuille d'incrémentales.
- Inconvénient(s) :
- Nécessite un outil adapté ;
- Consommera plus de capacité de stockage que de "simples" incrémentales.
- Avantage(s) :
En règle générale, on utilisera ses différentes méthodes ensemble : typiquement, on pourra imaginer une sauvegarde complète par semaine, puis une incrémentale les jours suivants, ce qui permet de garantir a minima un jeu propre tous les 7 jours et un temps de "reconstruction" très modéré. A l'inverse, on évitera de faire des incrémentales continuellement pendant un an... ce qui est pourtant le mode de fonctionnement de beaucoup de solutions assez basiques, et de scripts qu'on trouve un peu partout sur les Internets (à base de rsync ou de Borg, par exemple). Bien que j'apprécie beaucoup Borg, en l'occurrence, j'ai déjà pu constater ses limites dans le cas de jeux de sauvegardes s'empilant sur plusieurs mois : son index devient de plus en plus imposant (logique) et long à parcourir (logique aussi), mais surtout à reconstruire en cas de problème... Et restaurer des données "borg-isées" depuis plus d'un an dans un repository lourdement sollicité m'a déjà donné quelques sueurs froides.
Bref : prévoyez des "full" régulières (mais en faisant attention à la volumétrie) et limitez le nombre d'incrémentales.

Allez allez allez, on sécurise tout ça !
Il serait fort dommageable de ne pas aborder quelques problématiques de sécurité liées à la mise en place de vos sauvegardes. Jetons-y un œil, pour voir.
Commençons par le côté le plus simple : les flux réseaux. Parce que oui, même si vous avez mis en place un réseau dédié pour vos sauvegardes (et c'est bien !), ça n'implique pas que vous soyez à l'abri d'une fuite pour autant. D'une part parce que, d'un point de vue logique, toutes vos machines clientes vont se retrouver joignables à travers un même réseau (si vous aviez segmenté vos productions en VLAN/VRF/whatever avec tout plein de jolis firewalls, c'est dommage) ; d'autre part parce que, selon la solution que vous utiliserez, les flux risquent de passer en clair (et donc d'être écoutés par une machine vérolée) : ce sera le cas si vous passez par rsyncd, par exemple. A vous d'étudier la question en fonction de vos plateformes, de vos architectures et de vos analyses de risques. Prenez tout de même en compte que vous pouvez parfaitement déployer des firewalls sur toutes vos machines clientes également, limiter les accès aux seules applications de sauvegarde, et j'en passe... A noter également que, en 2019, il serait de bon ton de migrer vers une solution de sauvegarde qui permet de chiffrer les données et les transferts.
Deuxième problématique, plus complexe qu'il n'y paraît : le mode de sauvegarde. Allez-vous :
- "push" (pousser) vos données depuis les machines clientes vers vos serveurs de sauvegarde ?
- "pull" (tirer) ces mêmes données depuis ces derniers ?
On pourra noter, dans un premier temps, l'impact côté performances : si vous êtes en mode "push", alors vous devrez mettre en place une solution d'orchestration (ou une sacré planification manuelle, mais *spoiler* ça ne passe pas à l'échelle) pour éviter que toutes vos machines ne poussent en même temps vers vos serveurs. Sinon, il est fort probable que les congestions réseaux et autres surexploitations de ressources matérielles finissent par avoir raison de ceux-ci.
Deuxième point à prendre en compte : il va falloir gérer les autorisations d'accès à vos serveurs. Quelles machines clientes ont le droit de s'y connecter ? Comment gérez-vous les accès (clé SSH, passphrase, certificat...) ? Vos firewalls ? A l'échelle de quelques machines, ça va encore : quand on en a plusieurs milliers, le travail n'est plus le même.
Dans le cas du "pull", a priori il y a déjà moins de problématiques côté ordonnancement : c'est votre application de sauvegarde qui s'en chargera. Il faudra toujours faire attention au nombre de jeux de sauvegarde qui seront exécutés en même temps, mais ça reste plus simple à gérer.
En revanche, la contrainte de gestion des accès est dans ce cas plus complexe : vos serveurs vont devoir se connecter à vos clients. A TOUS vos clients. Avec des droits suffisants pour récupérer l'ensemble des données/filesystems souhaité.e.s (à noter que cette histoire de "droits suffisants" se retrouve aussi dans le cas du "push", mais on parle ici d'un élément extérieur qui se connecte à votre plateforme, ce qui n'a pas la même portée).
On pourra, enfin, également étudier des solutions un peu hybrides, qui utilisent des serveurs de "contrôle" (qui vont gérer les configurations de sauvegarde et ordonnancer les jeux, en envoyant l'ordre aux clients de démarrer le travail) et des "pools de stockage", qui peuvent être sur des serveurs différents des serveurs de "contrôle", qui accueilleront les flux et les volumétries.
3-2-1 : la sauvegarde qui vous va bien !
Un petit détour du côté des "bons vieux dictons de grand-mère", à présent : la règle du 3-2-1.
Cette règle est assez simple, et devra toujours rester dans un coin de votre tête :
- 3 : On conservera 3 copies de nos jeux de données. En comptant le jeu "de production", vous devez mettre en place 2 copies de sauvegarde (au cas où l'une des deux soit défaillante).
- 2 : On utilisera 2 supports de stockage différents et indépendants. Si mes données "de production" sont sur un disque dur, mes sauvegardes seront a minima sur un autre disque. A noter qu'un support "offline" est toujours intéressant : une sauvegarde sur un DVD ou une bande magnétique stockée dans le placard résistera d'autant mieux à un effacement accidentel ou un vilain pirate.
- 1 : On exportera un des jeux de sauvegarde à l'extérieur. En cas de panne/vol/incendie, il est impératif de pouvoir consulter/récupérer ses données depuis une source externe (un datacenter distant, un serveur dédié quelque part chez un hébergeur, une machine chez un proche...).

Sauvegarder x2 ou répliquer : that is the question
Revenons quelques instants sur la première règle du 3-2-1 : avoir plusieurs copies de sauvegarde, c'est bien, mais quelle est la meilleure façon de les mettre en place ?
Partons du principe que vous avez à votre disposition deux serveurs pouvant accueillir vos sauvegardes (chacun dans un datacenter différent), et quelques dizaines/centaines de machines à sauvegarder. Vous avez deux possibilités :
- Vous configurez deux jeux de sauvegardes sur chacun de vos clients, un vers chaque serveur ;
- Vous sauvegardez vos machines clientes sur le premier serveur, puis vous opérez une réplication des données du premier serveur vers le second.
Quelles différences entre ces deux solutions ? Voyons voir :
- Dans le premier cas, la mise en place est plutôt simple (d'un point de vue logique), tandis que dans le second il faut mettre en place un mécanisme de réplication additionnel ;
- Selon la plateforme de sauvegarde utilisée, cette réplication n'est pas forcément simple à mettre en place :
- Si vous stockez "à plat" vos fichiers (via rsync, Borg...), un rsync ou équivalent peut faire le travail (mais attention, plus grande sera la quantité de fichiers à répliquer, plus grande sera la probabilité que rsync ne tienne plus la cadence : on pourra alors privilégier des réplications au niveau filesystem, comme avec du ZFS sync par exemple) ;
- Si vous dépendez de bases de données, de catalogues ou autres pour l'indexation des sauvegardes, vérifiez bien que l'application que vous utilisez permet nativement de répliquer les données sur plusieurs sites : dans le cas contraire, une "simple" copie des données et quelques dumps ne vous permettront pas forcément de repartir au propre depuis votre second serveur...
- D'ailleurs, en admettant que vous puissiez configurer cette réplication dans votre application de sauvegarde, assurez-vous que cette dernière est bien elle-même sauvegardée : si vous perdez votre serveur de sauvegarde, vous devez être capables d'en remonter un rapidement, et de pouvoir exploiter les sauvegardes déjà créées. Ici, on retrouve donc les mêmes problématiques que pour la mise en place d'un PCA ou PRA applicatif, les solutions sont donc un peu les mêmes (clusters de bases de données, HA côté virtualisation...).
- Côté clients, si vous avez deux sauvegardes à effectuer, ça veut dire double impact sur les performances (CPU, réseau, disque...), et donc sur votre production, tandis que si vous répliquez vos sauvegardes, la charge n'est portée que sur le serveur en question ;
- En revanche, et c'est ici le point le plus important : si vous sauvegardez deux fois, vers deux cibles différentes, vous diminuez la probabilité de tomber sur un jeu de sauvegarde foireux.
Car oui : une sauvegarde foireuse, ça arrive (même si votre console de supervision est au vert). Admettons que vous utilisiez le modèle sauvegarde + réplication : si la première sauvegarde est corrompue (problème applicatif ou filesystem, attaque d'un méchant pirate...), vous risquez de répliquer cette corruption. Donc l'idée de faire 2 sauvegardes indépendantes est loin d'être saugrenue, même s'il faudra bien prendre en compte le surcoût côté performances et €€.

Superviser, ce n'est pas négociable
Terminons du coup sur cette histoire de supervision.
Vous avez mis en place vos sauvegardes, acheté le matériel adéquat pour ne pas dépendre de vieux cargos d'occasion, et tout paramétré au millimètre près pour impacter le moins possible votre production. Mais avez-vous la certitude que vos sauvegardes tournent bien ? A l'heure souhaitée ? Dans un délai raisonnable ? Vos serveurs de sauvegarde ont-ils encore de la place disponible ? Etes-vous capables de me dire, droit dans les yeux, que vos données et SGBD sauvegardé.e.s sont parfaitement exploitables ? Seriez-vous capable d'arrêter votre production, là, tout de suite, maintenant, pour opérer un exercice de restauration en conditions réelles ?
La sauvegarde est TRES souvent l'enfant le plus mal aimé d'un SI. On le néglige par manque de temps, de compétences, ou d'intérêt, et on s'en mord les doigts le jour fatidique. On y alloue très peu de ressources, on utilise du vieux matériel de récupération, et on ne surveille pas les messages d'erreur parce qu'il y a des tickets clients à traiter, ou un café qui nous attend.
ERREUR. GRAVE ERREUR.
Vos sauvegardes sont la ceinture de sécurité qui vous évitera le pare-brise numérique de la panne à 10 millions d'€.
- Formez vos équipes ;
- Mettez en place une supervision efficace, regardez-la tous les jours et traitez les incidents de sauvegarde comme tous les autres incidents de production ;
- Mettez également en place des tests de restauration réguliers (même manuels !) : gardez dans un coin des machines de test, faites des exercices pour valider l'intégrité des sauvegardes, si vos bases de données peuvent être relancées à partir des dumps de la veille, si vos procédures sont exploitables par toutes les équipes, y compris celles d'astreinte.
Je ne compte plus les structures dans lesquelles je suis intervenu et où on était incapable de me dire si telle ou telle plateforme était bien sauvegardée, et, si oui, dans quel état étaient ces sauvegardes. On joue déjà avec le feu avec de la blockchain-deeplearnisée-dockerisée à tout va sans prendre le temps de comprendre les cas d'usage de chaque techno, alors SVP prenez au moins le temps d'assurer vos arrières et les données de vos clients.
Exemple personnel
Allez, pour finir (promis !) sur un ton un peu plus léger, une dernière partie où je vais rapidement détailler comment j'ai pensé mon système de sauvegarde personnel (si ça peut donner des idées).
Pour contextualiser, je m'auto-héberge, c'est-à-dire que j'ai plusieurs machines (à mon domicile ou chez plusieurs hébergeurs) qui abritent différents services (Nextcloud, streaming multimédia, wikis, quelques blogs, etc). Si je me concentre sur le serveur qui est chez moi, il tourne sous Proxmox et hébergent une vingtaine de VM/conteneurs, le tout sur un espace de stockage ZFS.
J'ai donc mis en place, en essayant de rester KISS (Keep It Simple and Stupid) et en y consacrant au total 2 petites heures un WE :
- sur l'hôte qui porte mes VM/conteneurs, des snapshots réguliers (zfs-auto-snapshot) de tous mes volumes ZFS (tous les 1/4 d'heures, puis toutes les heures, puis tous les jours... pendant une semaine), pour remonter un service en 30s chrono en cas de soucis ;
- un système de dumps pour mes bases *SQL (automysqlbackup), qui dump toutes les bases et les versionne, puis qui appelle...
- ... un système de sauvegarde (Katarina) qui fait une sauvegarde en mode "fichier" de tout ce petit monde (dumps + VM/conteneurs + données personnelles du NAS) et assure différentes rétentions (15 jours ou 1 mois maximum) : je centralise ainsi, sur un volume ZFS dédié, toutes mes belles sauvegardes que je peux restaurer en quelques minutes via un bête rsync... ;
- ... puis j'utilise BorgBackup, qui va s'occuper d'exporter ces sauvegardes vers l'extérieur (un serveur chez mes parents, deux autres vers des hébergeurs dans les nuages) : il ne s'occupe donc que d'un seul "répertoire", qui englobe toute mes données importantes, et est utilisé comme outil d'archivage (un an de rétention, avec une très forte compression et de la déduplication).
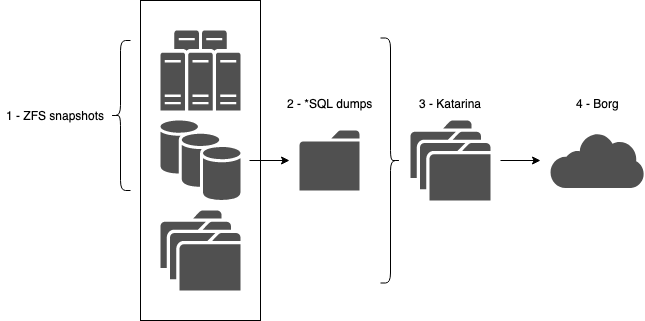
Et ce système, je le réplique sur les quelques autres plateformes "perso" que j'utilise, et ça marche tout seul :)